RAG für Marketing: Wie Retrieval Augmented Generation Ihre Content-Strategie revolutioniert
RAG macht Schluss mit KI-Halluzinationen und generischen Outputs. Lernen Sie, wie Sie mit Retrieval Augmented Generation markenspezifische, faktenbasierte Inhalte erstellen.
Inhaltsverzeichnis
RAG für Marketing: Wie Retrieval Augmented Generation Ihre Content-Strategie revolutioniert
Veröffentlicht am 6. Februar 2026 | 14 Min. Lesezeit
Die große Schwäche von ChatGPT & Co.
Sie haben es wahrscheinlich selbst erlebt: Sie bitten ChatGPT, einen Blog-Artikel über Ihr Produkt zu schreiben, und erhalten einen Text, der:
- Fakten über Ihr Unternehmen erfindet
- Preise falsch angibt
- Funktionen beschreibt, die es nicht gibt
- Generisch klingt und Ihre Markensprache ignoriert
Das ist kein Bug – es ist ein fundamentales Designproblem. Large Language Models (LLMs) wurden auf allgemeinen Internetdaten trainiert und wissen nichts über:
- Ihre aktuellen Produktspezifikationen
- Ihre Markenrichtlinien und Tonalität
- Ihre Kundenrezensionen und FAQs
- Ihre neuesten Kampagnen und Angebote
Die Lösung: RAG – Retrieval Augmented Generation.
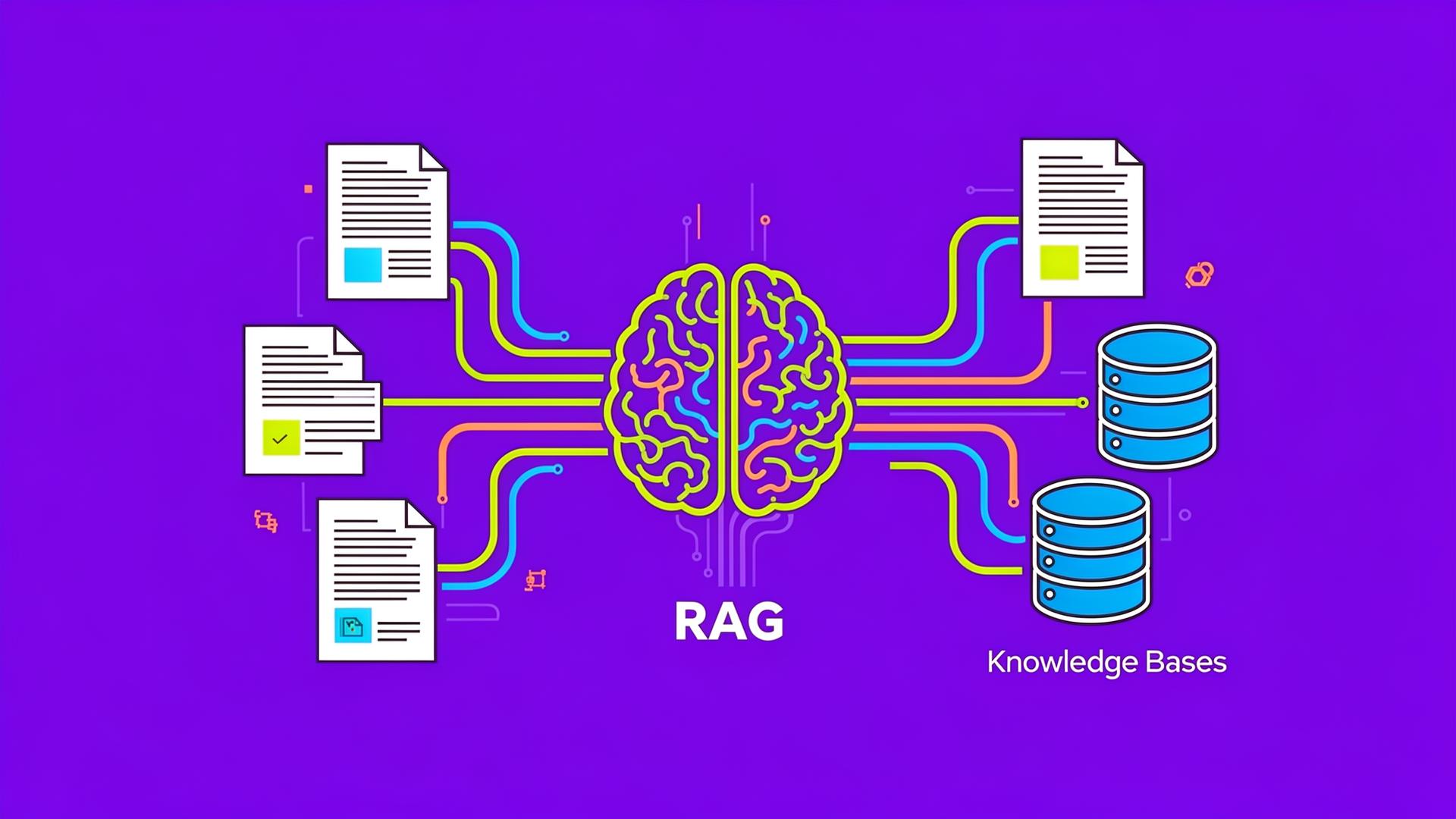
Was ist RAG?
RAG (Retrieval Augmented Generation) ist eine Architektur, die LLMs mit einer externen Wissensdatenbank verbindet. Statt nur auf Trainingswissen zurückzugreifen, ruft das Modell bei jeder Anfrage relevante Informationen aus Ihrer eigenen Datenquelle ab.
Der RAG-Workflow in 4 Schritten
| Schritt | Was passiert | Beispiel |
|---|---|---|
| 1. Anfrage | Nutzer stellt eine Frage | "Schreibe eine E-Mail über unsere neue Premium-Mitgliedschaft" |
| 2. Retrieval | System durchsucht Wissensdatenbank | Findet: Pricing-Dokument, Feature-Liste, bisherige E-Mail-Templates |
| 3. Augmentation | Relevante Dokumente werden dem Prompt hinzugefügt | LLM erhält Kontext mit echten Fakten |
| 4. Generation | LLM generiert basierend auf echten Daten | E-Mail mit korrekten Preisen und Features |
Technische Komponenten eines RAG-Systems
1. Wissensdatenbank (Knowledge Base)
- Produktdokumentationen
- Markenrichtlinien
- FAQ-Datenbanken
- CRM-Daten
- Bisherige Kampagnen
2. Embedding-Modell
3. Vektordatenbank
- Speichert Embeddings
- Ermöglicht schnelle Ähnlichkeitssuche
- Beispiele: Pinecone, Weaviate, Chroma
4. LLM (Large Language Model)
Warum RAG für Marketing unverzichtbar wird
1. Eliminierung von Halluzinationen
Ohne RAG erfindet ein LLM Fakten, wenn es keine kennt. Mit RAG antwortet es basierend auf echten Dokumenten – oder gibt zu, wenn keine Informationen verfügbar sind.
Vorher (Standard-LLM):
"Unser Premium-Plan kostet 49€/Monat und beinhaltet unbegrenzten Support." (komplett erfunden)
Nachher (RAG):
"Laut unserem aktuellen Pricing-Dokument kostet der Premium-Plan 79€/Monat und beinhaltet 24/7-Chat-Support sowie monatliche Strategy-Calls." (aus echtem Dokument)
2. Konsistente Markensprache
RAG kann Ihre Styleguides, Tone-of-Voice-Dokumente und bisherige Inhalte als Kontext nutzen.
Implementierung:
- Brand Voice Guidelines einbetten
- Beispiel-Texte als Referenz bereitstellen
- Forbidden Words und Preferred Terms definieren
3. Aktualität der Inhalte
LLMs haben ein Wissens-Cutoff-Datum. RAG ermöglicht Zugriff auf Echtzeit-Daten:
- Aktuelle Preise und Angebote
- Neueste Produktfeatures
- Aktuelle Kampagnen
- Live-Lagerbestände
4. Compliance und Rechtssicherheit
Marketing-Claims müssen faktisch korrekt sein. RAG ermöglicht:
- Verifizierte Produktaussagen
- Genehmigte Formulierungen
- Compliance-geprüfte Templates
- Audit-Trail durch Quellenangaben
Marketing Use Cases für RAG
Use Case 1: Produktbeschreibungen in Echtzeit
Problem: E-Commerce mit 10.000+ Produkten braucht einzigartige, SEO-optimierte Beschreibungen.
RAG-Lösung:
- Wissensbasis: Produktdatenbank, Lieferanten-Specs, Kundenrezensionen
- Output: Einzigartige Beschreibungen basierend auf echten Features
ROI-Beispiel:
| Metrik | Ohne RAG | Mit RAG |
|---|---|---|
| Produktbeschreibungen/Tag | 50 (manuell) | 500+ |
| Faktenfehler | 15% | <1% |
| SEO-Score (durchschnittlich) | 65 | 85 |
| Kosten pro Beschreibung | 8€ | 0,40€ |
Use Case 2: Personalisierte E-Mail-Kampagnen
Problem: Newsletter sollen persönlich wirken, aber generische KI-Texte klingen unpersönlich.
RAG-Lösung:
- Wissensbasis: CRM-Daten, Kaufhistorie, Interaktionsdaten
- Output: Hyper-personalisierte E-Mails mit echten Kaufvorschlägen
Use Case 3: Knowledge-Based Chatbots
Problem: Standard-Chatbots können nur vordefinierte FAQs beantworten oder halluzinieren bei komplexen Fragen.
RAG-Lösung:
- Wissensbasis: Support-Tickets, Produktdoku, Rückgaberichtlinien
- Output: Präzise Antworten auf jede Frage
Use Case 4: Lokalisierte Content-Erstellung
Problem: Internationales Marketing braucht kulturell angepasste Inhalte, nicht nur Übersetzungen.
RAG-Lösung:
- Wissensbasis: Lokale Styleguides, marktspezifische Kampagnen, regionale Besonderheiten
- Output: Kulturell adaptierte Inhalte
Use Case 5: Competitive Intelligence Content
Problem: Vergleichsseiten und Battle Cards müssen immer aktuell sein.
RAG-Lösung:
- Wissensbasis: Wettbewerber-Monitoring, eigene Stärken-Dokumente, Win/Loss-Analysen
- Output: Aktuelle Comparison-Content
Technische Implementierung: So starten Sie
Phase 1: Wissensbasis aufbauen (Woche 1-2)
Schritt 1: Datenquellen identifizieren
- Produktdatenbank exportieren
- Markenrichtlinien sammeln
- FAQ-Dokumente zusammenstellen
- Bisherige Top-Performing-Inhalte
Schritt 2: Daten aufbereiten
- Dokumente in Chunks aufteilen (500-1000 Token)
- Metadaten hinzufügen (Datum, Kategorie, Produkt)
- Duplikate entfernen
- Qualitätsprüfung
Schritt 3: Embeddings erstellen
- Embedding-Modell wählen (OpenAI, Cohere, etc.)
- Alle Chunks vektorisieren
- In Vektordatenbank speichern
Phase 2: RAG-Pipeline aufbauen (Woche 2-3)
Best Practices:
- Hybrid Search: Kombination aus Keyword + Semantik
- Chunk-Overlap: 10-20% Überlappung für Kontexterhalt
- Metadata-Filtering: Nach Aktualität, Kategorie filtern
Phase 3: Integration und Testing (Woche 3-4)
Metriken:
| Metrik | Zielwert |
|---|---|
| Antwortgenauigkeit | >95% |
| Quellenangabe | 100% |
| Durchschnittliche Latenz | <2s |
| Nutzerzufriedenheit | >4.5/5 |
Häufige Fehler und wie Sie sie vermeiden
Fehler 1: Zu große Chunks
Lösung: 500-1000 Token pro Chunk, mit Overlap.
Fehler 2: Veraltete Wissensbasis
Lösung: Automatisierte Sync-Pipelines, Versionierung, Verfallsdaten.
Fehler 3: Fehlende Metadaten
Lösung: Reichhaltige Metadaten beim Indexieren: Datum, Produkt, Region, Sprache.
Fehler 4: Blindes Vertrauen in Retrieval
Lösung: Reranking-Modelle, Relevanz-Threshold, Human-in-the-Loop.
Fehler 5: Keine Quellenangaben
Lösung: Citations im Output, Links zu Originaldokumenten.
Tools und Plattformen für Marketing-RAG
| Tool | Typ | Stärke | Für wen |
|---|---|---|---|
| LangChain | Framework | Flexibilität, Open Source | Entwickler-Teams |
| LlamaIndex | Framework | Dokumenten-fokussiert | Data Teams |
| Pinecone | Vektordatenbank | Skalierbarkeit, managed | Enterprise |
| Weaviate | Vektordatenbank | Open Source, Hybrid Search | Startups |
| CustomGPT | No-Code | Einfachheit | Marketing-Teams |
| Vectara | RAG-as-a-Service | All-in-one | Schnelle Implementation |
ROI-Kalkulation für Marketing-RAG
Investition (Jahr 1)
| Position | Kosten |
|---|---|
| Vektordatenbank (managed) | 2.400€/Jahr |
| LLM API-Kosten | 6.000€/Jahr |
| Embedding-Kosten | 1.200€/Jahr |
| Entwicklung/Setup | 15.000€ (einmalig) |
| Gesamt Jahr 1 | 24.600€ |
Einsparungen
| Bereich | Ohne RAG | Mit RAG | Ersparnis |
|---|---|---|---|
| Content-Erstellung (Stunden/Monat) | 80h | 20h | 60h × 75€ = 4.500€/Monat |
| Korrekturen/Fact-Checking | 20h | 2h | 18h × 75€ = 1.350€/Monat |
| Support-Tickets (Self-Service) | - | -30% | ~2.000€/Monat |
| Monatliche Ersparnis | 7.850€ |
Jährlicher ROI: (7.850€ × 12 - 24.600€) / 24.600€ = 283%
Die Zukunft: Agentic RAG
2026 entwickelt sich RAG weiter zu Agentic RAG – Systeme, die nicht nur Informationen abrufen, sondern aktiv handeln.
Ihr Aktionsplan
Diese Woche
- Inventar erstellen: Welche Dokumente gehören in Ihre Wissensbasis?
- Tool evaluieren: CustomGPT für schnellen Start testen
- Use Case priorisieren: Produktbeschreibungen, FAQs oder E-Mails?
Dieser Monat
- Pilotprojekt starten: Ein Use Case mit 100 Dokumenten
- Metriken definieren: Genauigkeit, Zeitersparnis, Nutzerzufriedenheit
- Team schulen: Grundlagen RAG für Marketing
Dieses Quartal
- Produktiv gehen: Ersten Use Case skalieren
- Iteration: Feedback sammeln, Wissensbasis erweitern
- ROI dokumentieren: Business Case für weitere Use Cases
RAG ist keine Zukunftstechnologie mehr – es ist die Gegenwart des professionellen KI-Einsatzes im Marketing. Wer heute startet, hat einen strukturellen Vorteil gegenüber Wettbewerbern, die weiterhin mit halluzinierenden LLMs arbeiten.
Der erste Schritt: Exportieren Sie heute drei Dokumente (Produktinfo, FAQ, Styleguide) und testen Sie einen RAG-Service wie CustomGPT. In einer Stunde sehen Sie den Unterschied. Erfahren Sie auch, wie Context Engineering RAG als eine von fünf Kontext-Schichten in eine ganzheitliche KI-Architektur einbettet.
Weitere Artikel
Diese Beiträge könnten Sie auch interessieren
 Strategie
StrategieWie nutze ich KI im Marketing? Der Praxis-Leitfaden 2026
Was ist KI-Marketing, wie nutzt man es, wie startet man? Der 5-Schritte-Plan plus realistische ROI-Daten — die Pillar-Antwort auf die meistgestellte Marketing-Frage 2026.
 Strategie
StrategieKI im Marketing nutzen: 7 Hebel mit messbarem ROI (2026)
Sieben konkrete Hebel, mit denen DACH-Marketing-Teams 2026 KI nachweislich produktiv machen — von der Prompt-Library bis zur Reporting-Automation. Mit ROI-Zahlen.
 Strategie
StrategieAI Brand Visibility 2026: Wie Marken in ChatGPT, Perplexity & Google AI Mode sichtbar werden
Pillar-Guide zu Agentic Engine Optimization (AEO): 6 Strategien, Tracking-Stack und Sentiment-Recovery, damit Ihre Marke in AI-Antworten zitiert wird — nicht nur bei Google rankt.